How goes it Señor? Continuing to share material from talks I’ve given but haven’t necessarily published, here’s what I said at Carnegie Mellon’s Heinz College last month. Titled “A Carative Approach to AI Governance”, it was a refinement of talks I’ve given over the last year. The word ‘carative’ is a contrast to the word ‘curative’ and is related to the holistic nature of nurses caring for patients as opposed to more pointed curing of patients that doctors are trained for. My earlier view on carative AI is in this blog post.
Positionality
I began with a positionality statement, highlighting:
1. Our par par nana (great great grandfather) Ishwar Das Varshnei being the first Indian to study at MIT in 1904-1905, taking glass manufacturing technology back to India, teaming up with Lokmanya Tilak to start the crowd-funded Paisa Fund Glass Works, and using its factory and school to fight for svarajya, a concept that not only included independence for India from the British, but also equality, liberty, and justice among the people.
2. Our baba (grandfather) Raj Kumar Varshney studying control engineering at Illinois and returning to India to apply the concepts to food production at the Allahabad Agricultural Institute. The institute’s founder Sam Higginbottom was an advisor to Mahatma Gandhi as he sought ways to reduce poverty.
3. My studying electrical engineering, working at a company with artificial intelligence as a focus, and trying to use that technology for equality and reducing poverty.
Further, I contrasted the morally-driven industrialist Henry Heinz (appropriate given the venue where I was speaking) and the muckraking investigative journalist Upton Sinclair in the early days of the processed food industry. I made the case that my worldview shaped by forefathers and foremothers is oriented towards that of Heinz. Heinz tried to work from the inside to improve things constructively while Sinclair worked from the outside to improve things by critically exposing ills.
Control Theory Perspective on AI Governance
Now to governance. A governor is a device to measure and regulate a machine. It is also known as a controller. Thus governance is the act or process of overseeing the control and direction of something. AI governance has lots of different definitions floating around these days, but they usually refer to responsible or trustworthy AI. The definitions may refer to laws and regulations, and may be quite philosophical. I recently heard 2023 predicted to be the “year of AI governance.” Interestingly, the etymological root for governance and cybernetics is the same Greek work kybernetes (cybernetics is an old word for AI-like things).
But instead of dwelling on laws, philosophy, or etymology for the time being, let’s come back to my engineering roots and look at a typical control system such as the one drawn below.

As an example, you can imagine this to be the thermostat in your home. You set a reference temperature that you want the home to be. If the temperature sensor measures too cold, then the controller in the thermostat triggers the furnace to turn on and stay on until the sensor finds the temperature has reached the reference. This is how control engineers view the world. Baba would think in this way not only for tractors as the system, but also fields of crops as the system.
What does the development lifecycle of machine learning look like to a control engineer? Societal values are the reference, data scientists are the controllers, modeling is the system input, the machine learning model is the system, testing is the sensor, facts are the measured output, and the different values and facts represents misalignment. There is necessarily a duality between what is valued and what is measured. Moreover, principles and value elicitation lead to the values, which act as the guiding light for the machine learning model.

Principles
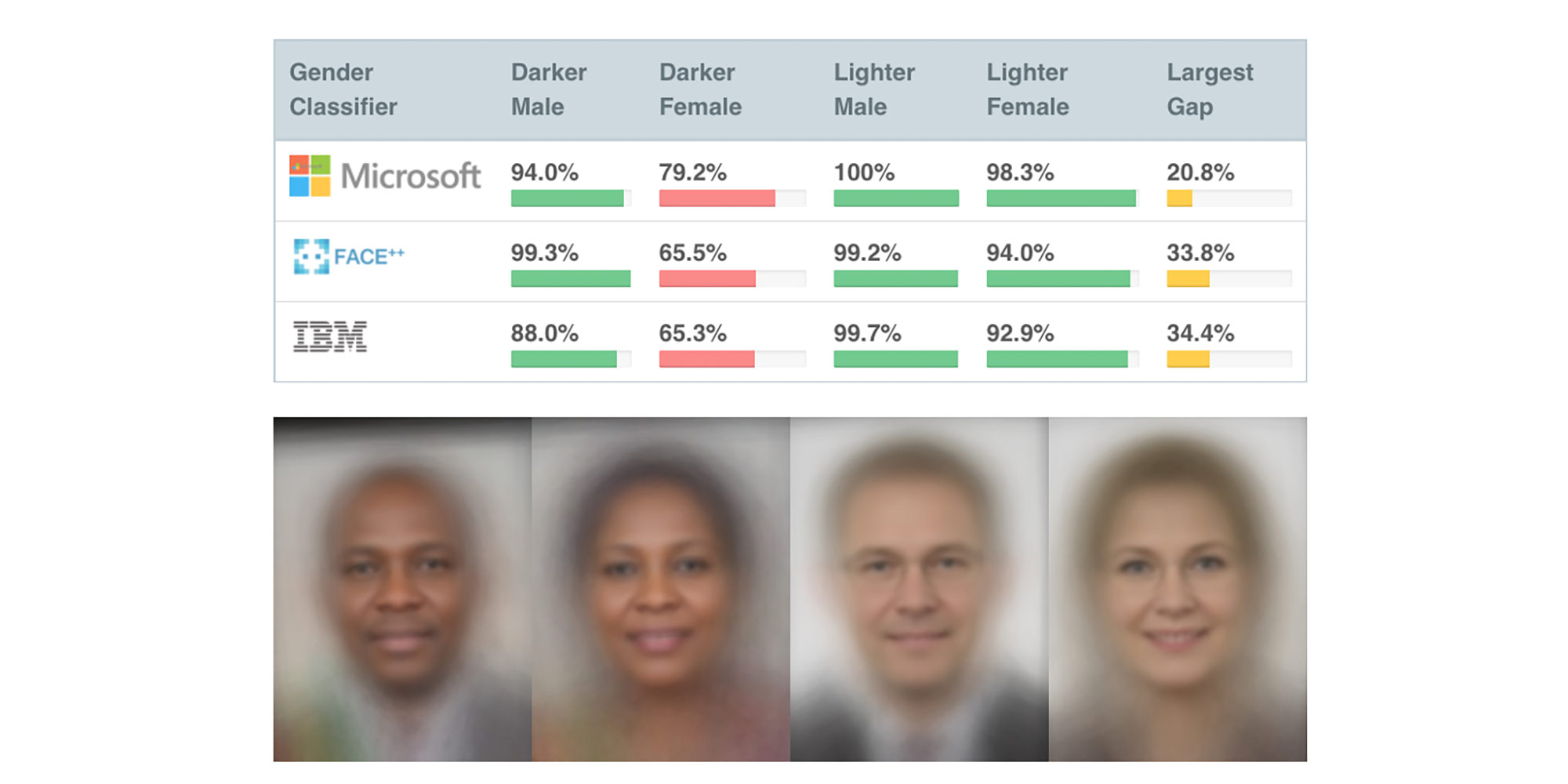
Schiff et al. survey AI ethics principles coming out of private industry, governments and civil society — most of which come from economically-developed countries and are based in Western philosophy. They find five common coarse-grained principles are espoused: (1) privacy, (2) fairness and justice, (3) safety and reliability, (4) transparency (which includes explainability), and (5) social responsibility and beneficence. There are some differences across sectors, however. Governments tend to further emphasize economic growth and productive employment as well as including discussions of ‘arms races’ between countries. Private industry mainly sticks to the five common principles and is sometimes accused of only putting out principles for the purpose of ethics washing. Civil society emphasizes shifting power to the vulnerable and may base their principles on critical theory.
Value Elicitation
Using the principles as a starting point, value elicitation is a process to specify the desired behavior of the system. Principles plus the context of the use case for which the machine learning model is being developed lead to values. We can think of four levels of value elicitation:
0. Should you work on this problem?
1. Which pillars of trustworthiness are of concern?
2. What are the appropriate metrics for those pillars of trustworthiness?
3. What are acceptable ranges of the metric values?
At Level 0, the Ethical OS helps us ask whether we should even be working on a problem or whether it is too against our values. Some of the considerations are:
1. Disinformation: does the system help subvert the truth at a large scale?
2. Addiction: does the system keep users engaged with it beyond what is good for them?
3. Economic inequality: does the system serve only well-heeled users or eliminate low-income jobs?
4. Algorithmic bias: does the system amplify social biases?
5. Surveillance state: does the system enable repression of dissent?
6. Loss of data control: does the system cause people to lose control of their personal data and the monetization it might lead to?
7. Surreptitious: does the system do things that the user doesn’t know about?
8. Hate and crime: does the system make bullying, stalking, fraud or theft easier?
There is no right or wrong answer to these considerations. Some people will be comfortable with some and not with others. Elicitation is all about getting those preferences.
At Level 1, assuming that accuracy or other similar predictive performance measures are always important, we ask which among (1) fairness, (2) explainability, (3) uncertainty quantification, (4) distributional robustness, (5) adversarial robustness, and (6) privacy are of concern for the use case. People find it difficult to directly give their preferences about this, so some more appropriate dimensions are asking whether:
1. Disadvantage: decisions have the possibility of giving systematic disadvantage to certain groups or individuals
2. Human-in-the-loop: the system supports a human decisionmaker
3. Regulator: regulators (broadly construed) audit the model
4. Recourse: affected users can challenge decisions
5. Retraining: the model will be frequently retrained
6. People data: the system uses data about people, including possibly sensitive information
7. Security: the data and model are kept behind lock-and-key
The answers to these questions can ground a conditional preference network (CP-net) that eventually determines which pillars of trustworthiness are important for a given use case as follows.

There’s a recent extension of CP-nets called SEP-nets that could even go as far as relating the context of use cases to the appropriate dimensions to get to the pillars of trustworthiness.
Level 2 elicitation for specific quantitative metrics is interesting. For example, as it is well known, there is a boatload of fairness metrics. Elicitation could be done by having a person ponder about their use case in terms of worldviews. An alternative, recently proven out in practice, is to do metric elicitation by having people compare confusion matrices in a pairwise fashion. Level 3 elicitation for acceptable metric value thresholds or ranges is hard, and I don’t think there are the greatest of proven methods yet. In my book, I suggest creating many different models to visualize what is possible and also posing this as a variation on a trolley problem. It is also not fully clear how to elicit values from a group of people since typical aggregation methods (e.g. voting) drown out minority voices. Perhaps facilitated participatory design sessions are the only decent way.
Testing and Facts
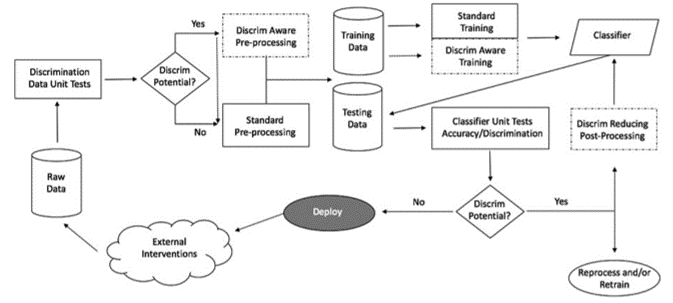
Machine learning testing is different from regular software testing because of the oracle problem: we don’t know what the right answer is supposed to be. The way around it is through metamorphic relations: feeding in two different data points for which we don’t know what the right answer is supposed to be, just that it should be the same for both inputs. Generating test cases that have good coverage is very much an open problem, and not one solved simply through adversarial samples. Testing should be done not only for accuracy, but for all of the metrics from Level 2 value elicitation and accompanied by uncertainty estimates.
Test results are also called facts in the parlance of the AI FactSheets initiatve. They can be rendered out in a factsheet that allows for good comparison with values and permits understanding of misalignment. Different consumers of factsheets may require different amount of detail. The system developers can declare that their facts conform to the values with a kind of factsheet known as a supplier’s declaration of conformity (SDoC).

Something’s Missing
Control theory, pillars of trust, quantitative test results, acceptable ranges of metrics and all that jazz is great — it has the flavor of consequentialism. In fact, the consequentialism vs. deontology (outcomes vs. actions) debate is the framing of and one of the main debates in AI ethics. For example, we explored it in the context of the Pac-man game a few years ago.
However, this debate (and AI ethics more generally) is missing something. Consequentialism vs. deontology is a very Western philosophy-centered debate. Birhane et al. ask why we should think that Western philosophy captures everything. They further say “The field would benefit from an increased focus on ethical analysis grounded in concrete use-cases, people’s experiences, and applications as well as from approaches that are sensitive to structural and historical power asymmetries.” To me, they are pointing to care.
Lokmanya Tilak (the person our par par nana teamed up with to start the glass works) based a lot of his political philosophy on the Bhagavadgītā, with a focus on one aspect of it: niṣkāma karma, or desireless action. But there’s a second-order reading of the Bhagavadgītā that goes beyond this. Carpenter writes: “Kṛṣṇa speaks in terms of duties—duties whose claim on us cannot be over-ridden by any other sort of consideration. I want to dispute this characterisation of Kṛṣṇa, firstly, to contest the interpretation of the niṣkāma karma (desireless action) principle on which the charge of deontology rests. But I want to dispute it also, and more importantly, because I think Kṛṣṇa’s moral voice is rather more rich and interesting than our classifications of ‘deontological’ and ‘consequentialist’ (even broad consequentialist) allow.”
Furthermore, she says that “Arjuna is not the exclusive author of his own law; the social order into which he was born, the place he was born into, the endowments with which he came to it, and even his personal history (where this refers only very partially to his own choices), wrote a ‘law’ just for him.” She says that the main message of Kṛṣṇa’s philosophy is svadharma, one’s personal duty based on station, reputation, skill and family — all of these things together are svabhāva. (The sva- prefix is the same as in svarajya, self-.) This is the context and grounding Birhane et al. speak of that arise in other philosophies. There is no one universal, generalizable, abstract law or duty for everyone. This perspective is different from both consequentialism and deontology as it is seeking right outcomes and right actions based on context and abilities. It is also different from moral particularism, because there is still some sense of right and wrong — it is not a complete free-for-all.
Carative Approach to AI
What is AI’s svadharma? The goal of machine learning practitioners is usually generalization and abstraction. We usually want to do the same exact thing without thinking about the differences between decisions in lending, college admissions, hiring, parole, etc. They are all just binary classification problems and we use the same algorithms. We don’t bring in context, so there is no svabhāva and there is thus no svadharma.
To bring in svadharma, what we need instead is a carative approach to AI. We must start with the real-world problem as experienced by the most vulnerable, listen to them and understand their values (this is the context), meet them where they are and work toward a solution to their problem all the way to the end, and conduct a qualitative assessment of the entire solution by interviewing the affected communities. We did precisely that in a project with Simpa Networks on scoring applications for home solar panels in rural Indian villages, and it worked.


This is also the paradigm of action research. In (1) defining the problem, (2) planning how to solve the problem, (3) acting upon the solution, (4) evaluating the solution, and (5) learning and generalizing from it, action research centers the values of members of marginalized groups and includes them as co-creators. In caring professions like nursing, practitioners do the first four steps, but usually not the fifth. That’s the research, and it is not against the spirit of having one’s own duty. We should learn to figure out best practices on pillars of trust, metrics, ranges of metric values, etc. from working on real problems. Although this amounts to an uncountably infinite variety of AI contexts, use cases, and problems, we can pick a few prototypical examples across industries and sectors, and generalize from them, perhaps using SEP-nets.


Conclusion
AI governance is a control problem, but it does not make sense without context. We have been blinded by the use of Western philosophy as a starting point; maybe neither consequentialism nor deontology are the right way to look at precise and grounded applications of a general-purpose technology like AI. A specific AI system’s svadharma comes from its lineage, its creators, its capabilities, and especially its context for use. Carative AI governance implies a focus on the entire development lifecycle, not just modeling, and making choices that center the most marginalized throughout.